
Apple’s Create ML is a nice feature with an unclear purpose
Apple announced a new feature for developers today called Create ML. Because machine learning is a commonly used tool in the developer kit these days, it makes sense that Apple would want to improve the process. But what it has here, essentially local training, doesn’t seem particularly useful.
The most important step in the creation of a machine learning model, like one that detects faces or turns speech into text, is the “training.” That’s when the computer is chugging through reams of data like photos or audio and establishing correlations between the input (a voice) and the desired output (distinct words).
This part of the process is extremely CPU-intensive, though. It generally requires orders of magnitude more computing power (and often storage) than you have sitting on your desk. Think of it like the difference between rendering a 3D game like Overwatch and rendering a Pixar film. You could do it on your laptop, but it would take hours or days for your measly four-core Intel processor and onboard GPU to handle.
That’s why training is usually done “in the cloud,” which is to say, on other people’s computers set up specifically for the task, equipped with banks of GPUs and special AI-inclined hardware.
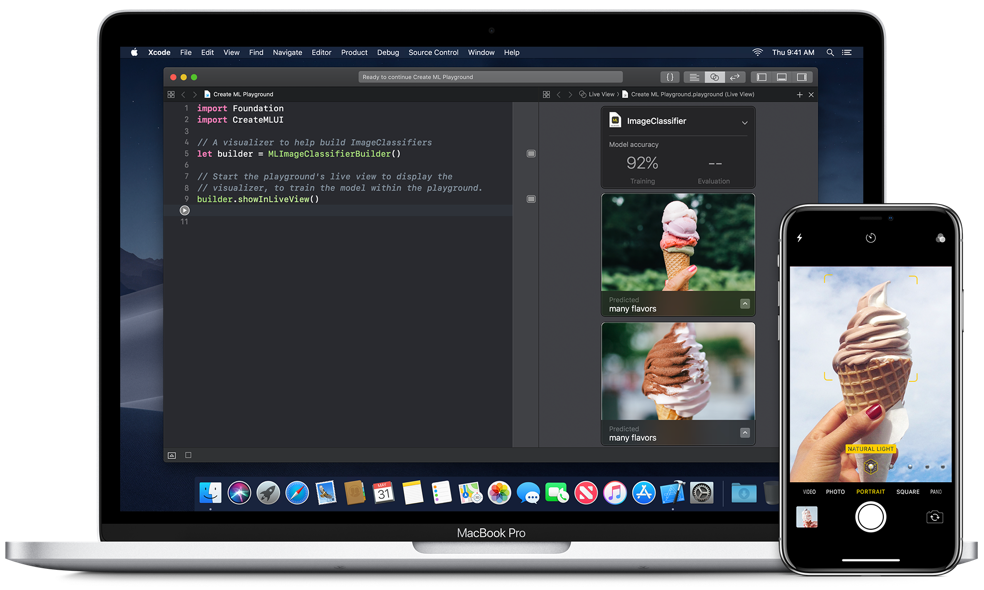 Create ML is all about doing it on your own PC, though: as briefly shown onstage, you drag your data onto the interface, tweak some stuff and you can have a model ready to go in as little as 20 minutes if you’re on a maxed-out iMac Pro. It also compresses the model so you can more easily include it in apps (a feature already included in Apple ML tools, if I remember correctly). This is mainly possible because it’s applying Apple’s own vision and language models, not building new ones from scratch.
Create ML is all about doing it on your own PC, though: as briefly shown onstage, you drag your data onto the interface, tweak some stuff and you can have a model ready to go in as little as 20 minutes if you’re on a maxed-out iMac Pro. It also compresses the model so you can more easily include it in apps (a feature already included in Apple ML tools, if I remember correctly). This is mainly possible because it’s applying Apple’s own vision and language models, not building new ones from scratch.
 I’m trying to figure out who this is for. It’s almost like they introduced iPhoto for ML training, but as it’s targeted at professional developers, they all already have the equivalent of Photoshop. Cloud-based tools are standard and relatively mature, and like other virtualized processing services they’re quite cheap, as well. Not as cheap as free, naturally, but they’re also almost certainly better.
I’m trying to figure out who this is for. It’s almost like they introduced iPhoto for ML training, but as it’s targeted at professional developers, they all already have the equivalent of Photoshop. Cloud-based tools are standard and relatively mature, and like other virtualized processing services they’re quite cheap, as well. Not as cheap as free, naturally, but they’re also almost certainly better.
The quality of a model depends in great part on the nature, arrangement and precision of the “layers” of the training network, and how long it’s been given to cook. Given an hour of real time, a model trained on a MacBook Pro will have, let’s just make up a number, 10 teraflop-hours of training done. If you send that data to the cloud, you could choose to either have those 10 teraflop-hours split between 10 computers and have the same results in six minutes, or after an hour it could have 100 teraflop-hours of training, almost certainly resulting in a better model.
That kind of flexibility is one of the core conveniences of computing as a service, and why so much of the world runs on cloud platforms like AWS and Azure, and soon dedicated AI processing services like Lobe.
My colleagues suggested that people who are dealing with sensitive data in their models, for example medical history or x-rays, wouldn’t want to put that data in the cloud. But I don’t think that single developers with little or no access to cloud training services are the kind that are likely, or even allowed, to have access to privileged data like that. If you have a hard drive loaded with the PET scans of 500,000 people, that seems like a catastrophic failure waiting to happen. So access control is the name of the game, and private data is stored centrally.
Research organizations, hospitals and universities have partnerships with cloud services and perhaps even their own dedicated computing clusters for things like this. After all, they also need to collaborate, be audited and so on. Their requirements are also almost certainly different and more demanding than Apple’s off the shelf stuff.
I guess I sound like I’m ragging for no reason on a tool that some will find useful. But the way Apple framed it made it sound like anyone can just switch over from a major training service to their own laptop easily and get the same results. That’s just not true. Even for prototyping and rapid turnaround work it doesn’t seem likely that a locally trained model will often be an option. Perhaps as the platform diversifies developers will find ways to make it useful, but for now it feels like a feature without a purpose.







from TechCrunch https://ift.tt/2swH5Sq

No comments
Post a Comment